
23 Juin AI Search et Grounding : un hit de ChatGPT-User n’est pas une citation
OLIVIER MARTINEZ
Depuis 2022, Olivier Martinez accompagne dirigeants, managers et équipes dans la compréhension, l’expérimentation et le déploiement de l’IA générative en particulier des LLM. Après plus de 15 ans comme product manager dans les médias numériques, il s’est spécialisé sur l’IA à Sciences Po entre 2020 et 2022. Fondateur de 255hex.ai et co-fondateur de Futursens, il intervient avec une approche à la fois stratégique et opérationnelle. Il est également professeur affilié à Sciences Po Executive Education.
Quand on fait une recherche internet avec ChatGPT, le chatbot donne une réponse avec des sources. Mais ce qu’il montre ne dit presque rien de ce qu’il a réellement récupéré, utilisé ou ignoré.
Quand vous posez une question à ChatGPT et que l’agent conversationnel va chercher des informations en temps réel sur le web, sa réponse arrive accompagnée de petites pastilles de sources, de liens cliquables, et d’un panneau “Sources” qui se déplie sur le côté pour ChatGPT.
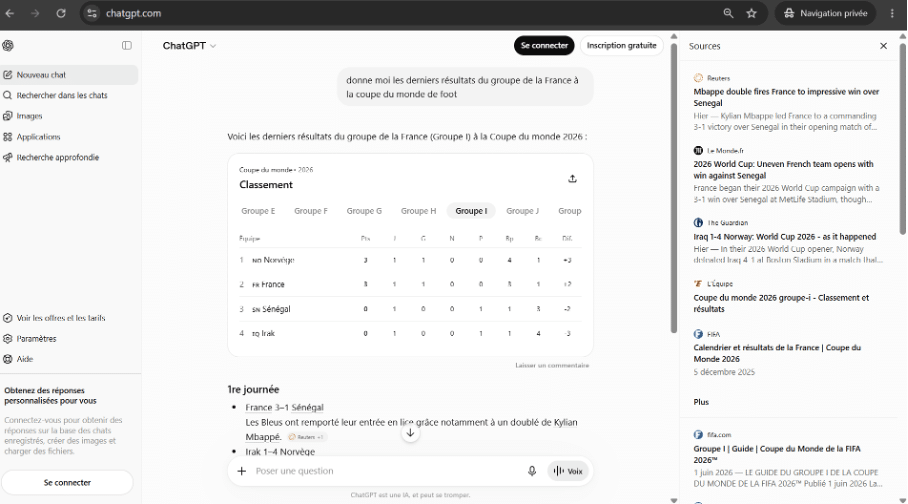
Cet ensemble donne une impression de transparence : on voit d’où vient la réponse, on peut cliquer, vérifier. C’est précisément ce que la fonctionnalité est censée produire : une réponse appuyée sur des documents, et non sortie uniquement des paramètres d’entrainement du modèle de langage utilisé. D’un point de vue technique cela s’appelle le Grounding, c’est à dire l’ancrage d’une réponse générée dans des sources citables et traçables.
Pourtant cet affichage des sources, cette mise en scène, est une fenêtre partielle, et parfois trompeuse, sur ce qui s’est réellement passé depuis la requête utilisateur jusqu’à la réponse générée.
Entre les pages web que le système est allé récupérer et les sources qu’il finit par montrer dans les réponses aux utilisateurs, il y a une chaîne de décisions que personne ne voit. Cette chaîne reste une boîte noire : ce qui se joue à l’intérieur de l’outil, les arbitrages qui retiennent une source plutôt qu’une autre et un passage plutôt qu’un autre, n’est pas accessible.
Deux points d’observation restent toutefois disponibles. Côté utilisateur, il y a l’interface : la réponse produite et les sources qu’elle affiche. Côté éditeur, il y a les logs serveur, qui enregistrent quels robots passent, quand, et sur quelles pages, ainsi que la mesure du trafic entrant identifié. Mis ensemble, ces deux points de vue racontent une histoire assez différente de celle que suggère le “simple” écran de la réponse générée pour un utilisateur à un instant T.
Deux gestes, un même mécanisme
Il faut en premier définir ce qu’est le Grounding dans son acception technique.
Historiquement un modèle de langage (LLM) ne se connecte pas à internet pour générer une réponse. Il répond “de mémoire”, à partir de ce qu’il a appris pendant son entraînement. On parle de réponse paramètrique. Si le sujet a été mis à jour depuis la phase d’entrainement, le modèle n’en sait rien et produit alors une réponse qui ne correspond plus à la réalité.
Pour pallier cette difficulté, on a mis en place un mécanisme qui s’appelle le grounding, ou ancrage en Français. Un modèle groundé va chercher des contenus extérieurs, dans nos exemples ici des pages web – mais ça pourrait être une base de données propriétaire et fermée – et construit sa réponse à partir de ces contenus, et pas uniquement à partir des données apprises lors de son entrainement. C’est cela qu’on appelle le grounding, l’ancrage de la réponse dans des sources : les affirmations sont reliées à des sources qui sont visibles et auditables par l’utilisateur. Cela permet, entre autres, d’obtenir des réponses plus proches de la réalité des faits à un instant T.
Ce mécanisme se déclenche dans deux grands types de situations.
Quand vous posez une question et que le système va chercher de quoi y répondre. C’est le cas le plus général du grounding :
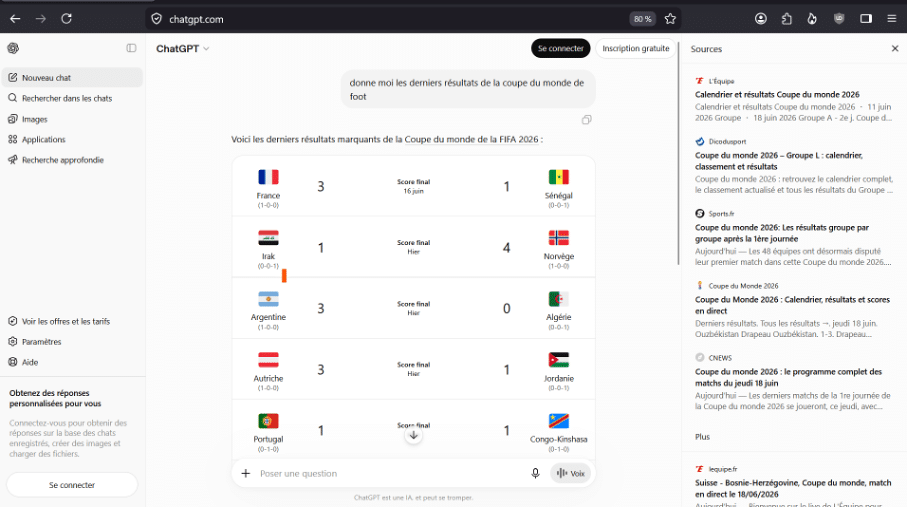
Le second type, c’est quand vous fournissez vous-même une URL en demandant au chatbot de la résumer ou de l’analyser. On parle alors d’url context :
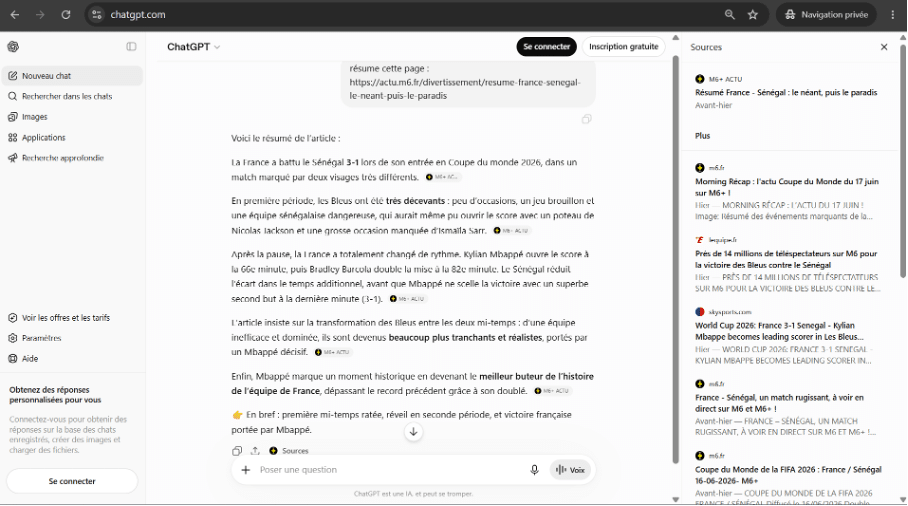
`Dans les deux cas, un bot part récupérer du contenu sur le web pour répondre à la requête. Chez OpenAI, ce robot porte un nom : ChatGPT-user.
Point de terminologie :
Le terme grounding dans son acception technique historique, désigne l’ensemble des mécanismes et étapes qui permettent d’attacher des sources externes, identifiables et vérifiables, à une réponse générée par un modèle de langage. Le grounding désigne donc à la fois un objectif, un processus et un critère de qualité : la réponse doit être ancrée dans des sources ou des informations externes, et ces sources doivent pouvoir être inspectées, citées, vérifiées ou contestées.
Il y a quelques jours, le SPUR a publié une nomenclature permettant de distinguer cinq étapes d’usage d’un contenu par les IA. Le terme grounded est employé dans cette nomenclature de manière plus étroite car il définit une seule des étapes que la définition technique historique englobe. En l’occurrence selon la définition du SPUR, le grounding c’est uniquement le moment où un contenu est chargé dans le contexte de génération de la réponse par l’agent conversationnel.
Nous avons donc deux définitions pour le même mot :
- d’un côté, grounding au sens technique “IA” : tout le mécanisme qui permet de produire une réponse ancrée dans des sources, avec récupération, sélection, injection, génération, citation éventuelle et vérification
- de l’autre, grounding au sens SPUR : un événement de télémétrie précis indiquant qu’un contenu est entré dans le contexte du modèle et pouvant influencer la sortie générée par le modèle
Dans cet article, nous utilisons grounding dans le sens technique historique.
Beaucoup de contenu aspiré, peu de trafic rendu
ChatGPT-user n’est pas le seul bot qu’OpenAI envoie sur le web. Avant de regarder ce qui est fait des contenus par ce dernier, il faut savoir qu’il existe plusieurs bots et crawlers, qui ne font pas le même métier.
Trois finalités coexistent historiquement :
- La première est l’entraînement : un robot (GPTbot du côté d’OpenAI) collecte des contenus pour constituer les jeux de données qui serviront à entraîner les modèles.
- La deuxième est l’indexation : un autre robot (OAI-SearchBot) parcourt et indexe les contenus, comme le ferait un moteur de recherche. L’objectif est de constituer des bases de contenus et des index pouvant être délivrés instantanément aux utilisateurs.
- La troisième est l’assistance en temps réel : un robot agit en fonction d’une demande spécifique d’un utilisateur afin de récupérer des éléments pour lui fournir une réponse. C’est le grounding et l’url context dont il est question ici, assurés par ChatGPT-user.
Pour être exhaustif, à ces trois “métiers” historiques s’ajoute désormais une catégorie émergente, celle des “agents” qui naviguent et agissent à la place de l’utilisateur.
Cette distinction de finalité a une conséquence directe pour les éditeurs. Car tous les bots ne respectent pas de la même manière les consignes d’interdiction d’accès du robots.txt.
Les robots d’entraînement et d’indexation sont censés respecter à la lettre ces consignes. C’est en tout cas ce qu’OpenAI, par exemple, précise dans sa documentation. En revanche cette même documentation précise que le robot qui répond en temps réel à une requête (ChatGPT-User) ne respecte pas obligatoirement une consigne d’interdiction exprimées dans le robots.txt.
Le cas d’OpenAI n’est pas isolé sur cette pratique. D’autres comme Perplexity appliquent la même politique. La justification généralement donnée est que l’agent conversationnel agit au nom et en place d’un utilisateur : ce n’est pas l’agent conversationnel qui vient chercher seul le contenu, c’est en réponse à une demande humaine.
Quand on observe les chiffres globaux dans le détail, c’est précisément cette finalité d’assistance en temps réel qui domine dans la présence des bots et crawlers utilisés par les géants de l’IA. En 2025, le nombre de passages de bots sur les sites a explosé, et ChatGPT-user est le bot le plus fréquemment observé, loin devant tous les autres (Tollbit et les données fournies au Geste par BotsCorner). Donc actuellement, le bot le plus présent et actif sur les sites est aussi le plus libre, celui qui respecte le moins les consignes.
Or cette activité de récupération est sans commune mesure avec le trafic renvoyé en retour vers les sites des éditeurs. Le déséquilibre se mesure par un ratio entre le nombre de pages crawlées et le nombre de visiteurs réorientés vers les sites. Depuis janvier 2025, ce ratio s’est amélioré pour OpenAI, passant d’environ 1 217 pages crawlées pour un visiteur renvoyé à environ 857 pour un (Cloudflare). L’ordre de grandeur reste considérable si on le compare à un moteur classique : chez Google, le même ratio tourne autour de cinq pour un. En clair, là où Google consulte cinq pages pour vous renvoyer un visiteur, ChatGPT en consulte plusieurs centaines.
Le trafic que ChatGPT renvoie progresse, certes : il augmente de 206 % entre janvier 2025 et janvier 2026 (Semrush). Mais il reste marginal dans le trafic référent global des sites, dans les meilleurs cas autour de 1 à 2 % des referrals depuis le début de 2026 (Semrush, Ahrefs). On aspire donc beaucoup de contenu, on en renvoie peu de trafic, et pour aggraver la situation l’industrie documente assez mal tout le processus d’utilisation des contenus dans les réponses générées. Laissant les éditeurs et l’industrie de web dans le brouillard.
En revanche, point positif, tous les éditeurs peuvent suivre le trafic entrant vers leur site : tous les liens sortants de ChatGPT sont marqués d’un paramètre utm_source=chatgpt.com, ce qui les rend identifiables dans les statistiques et les outils de mesure d’audience.
Un exemple de grounding quand on fait une demande
Méthodologie : j’ai volontairement pris un exemple de requête sans finalité exprimée. Les tests ont été effectués à partir de la version gratuite de ChatGPT sans compte utilisateur, dans un navigateur en session privée et à partir d’un VPN et de plusieurs IP situées en France.
I :
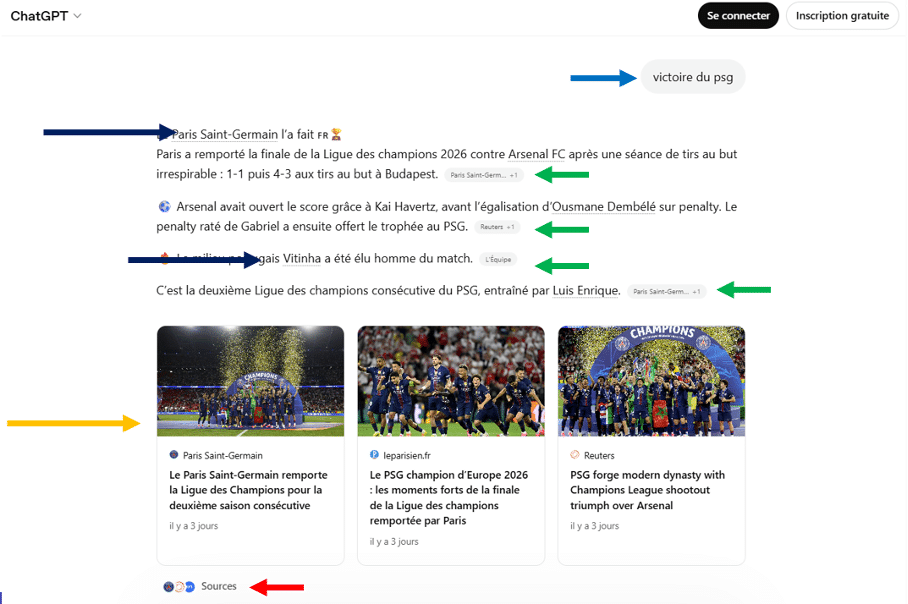
J’ai envoyé à ChatGPT une requête (la flèche bleue) : “victoire du psg”. La réponse est arrivée sous la forme attendue : un texte qui raconte la finale, ponctué de pastilles de sources (les flèches vertes), accompagné de trois vignettes d’articles illustrées (la flèche jaune), d’un lien “Sources “ en bas (la flèche rouge), et de liens internes à ChatGPT,
appelé “liens d’entité” (les flèches noires).
II :
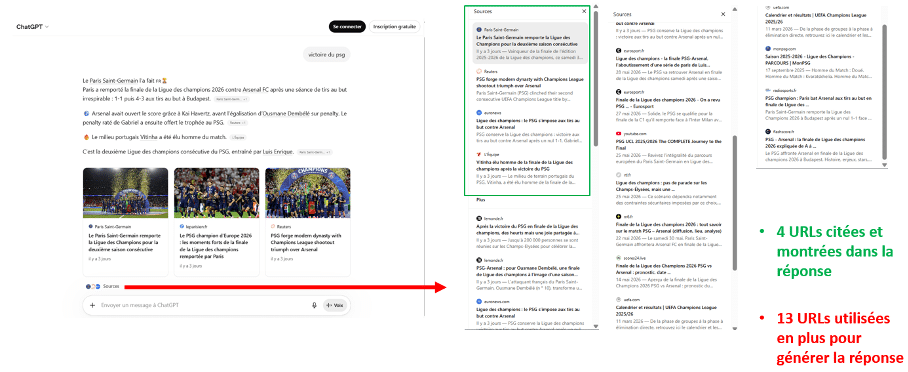
À l’écran, donc, quatre URLs apparaissent : celles qui sont citées dans le corps de la réponse et montrées dans les vignettes. C’est ce que voit l’utilisateur, et c’est sur cette base qu’il jugera de la fiabilité de la réponse. En déroulant le panneau complet des sources, le tableau change déjà : le système a utilisé treize URLs supplémentaires pour produire sa réponse, au-delà des quatre mises en avant. Le modèle ne reçoit jamais “tout le web”, mais il a manifestement consulté et exploité bien plus que ce qu’il expose dans sa réponse. Il y a donc ce qui est montré et ce qui est utilisé.
III :
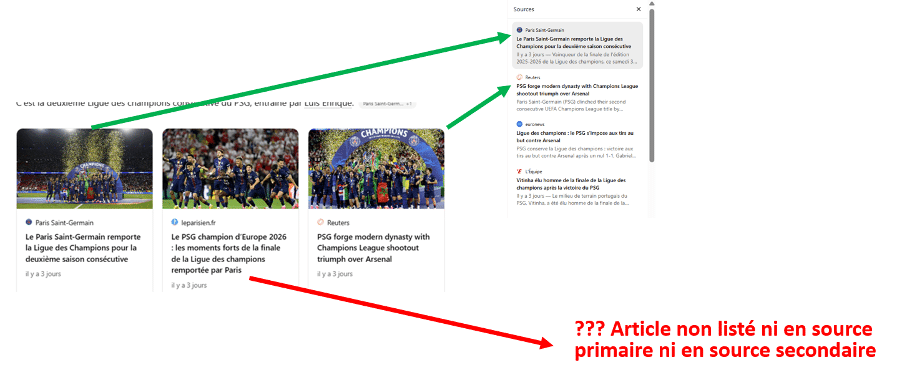
Un autre détail mérite notre attention. Parmi les contenus montrés sous forme de vignettes dans la réponse figure un article qui n’apparaît ni dans les sources primaires ni dans les sources secondaires listées. Il est affiché, visible, mis en avant graphiquement, mais il n’est rattaché à aucune des catégories de sources que le système prétend exposer. Il est montré, donc, sans être listé. La frontière entre “ce qui est cité” et “ce qui est utilisé” se double ici d’une troisième zone : “ce qui est montré mais non répertorié “.
IV :
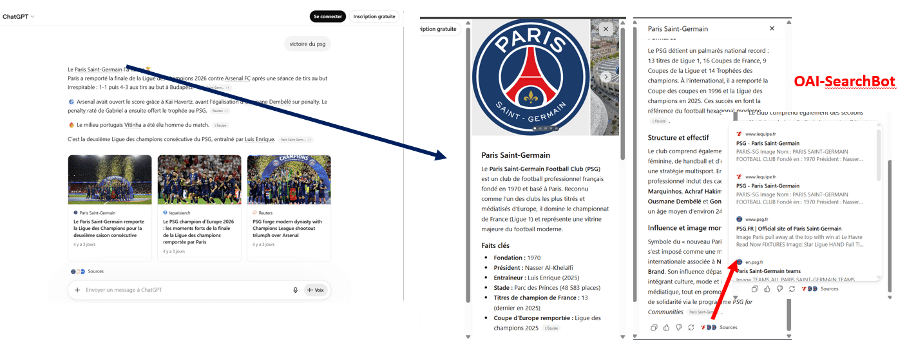
Enfin dernière observation sur ce cas : quand on clique sur un lien “entité”, une fenêtre apparait sur le côté droit. Cette fenêtre propose des informations à propos de l’entité elle-même, comme une sorte de base de connaissance ou de wiki. Les informations de ce wiki sont elles-mêmes sourcées. A cet endroit, le bot utilisé est celui de l’indexation pour les sources indexées à l’avance, et ChatGPT-User pour des sources “fraîches”. Dans ces réponses “entités” une partie des sources ont été indexées à l’avance contrairement aux sources utilisées pour la réponse principale.
Donc ici OAI-SearchBot, le robot d’indexation, intervient en parallèle de ChatGPT-user sur la même requête. Techniquement il y a une séparation : indexation / assistance en temps réel. Mais cette séparation théorique entre le métier d’indexation et celui de réponse en temps réel est, en pratique, poreuse, et pour l’utilisateur cette séparation n’existe pas. Plusieurs robots aux statuts différents travaillent ensemble à plusieurs niveaux pour une seule réponse à une requête.
Quand on fournit soi-même l’URL
Le cas de l’url context est aussi très instructif, parce qu’il contredit une intuition très répandue. Lorsqu’on colle un lien et qu’on demande un résumé, on suppose que le système va lire cette page, et seulement cette page, pour produire sa réponse. J’ai fourni à ChatGPT l’URL d’un article du Parisien portant sur une affaire judiciaire, en lui demandant de le résumer.
I :
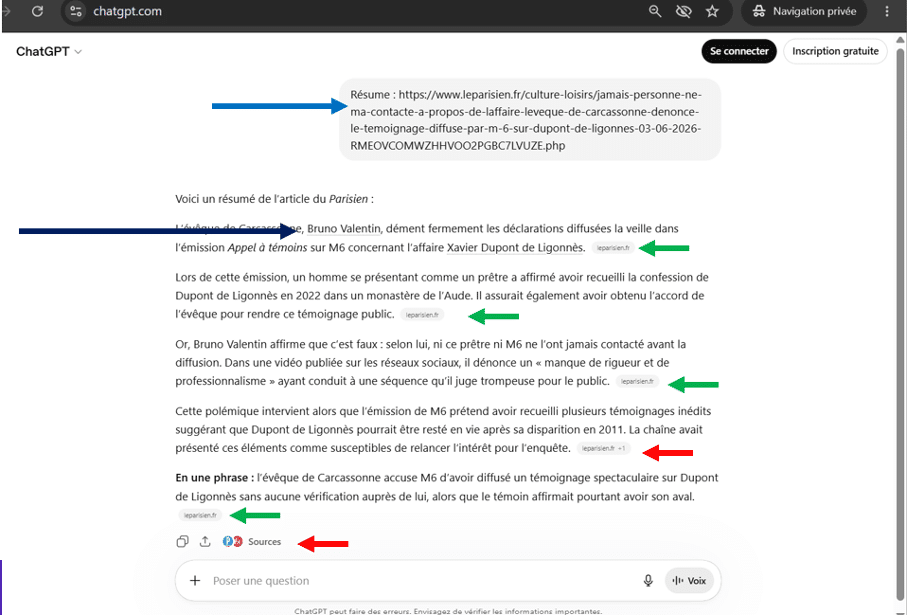
Voici la réponse. Comme pour l’exemple du PSG, il y a la requête (flèche bleus), les sources (flèches vertes et rouge) alors que la demande ne portait que sur une source, et des liens entités (flèche noire).
II :
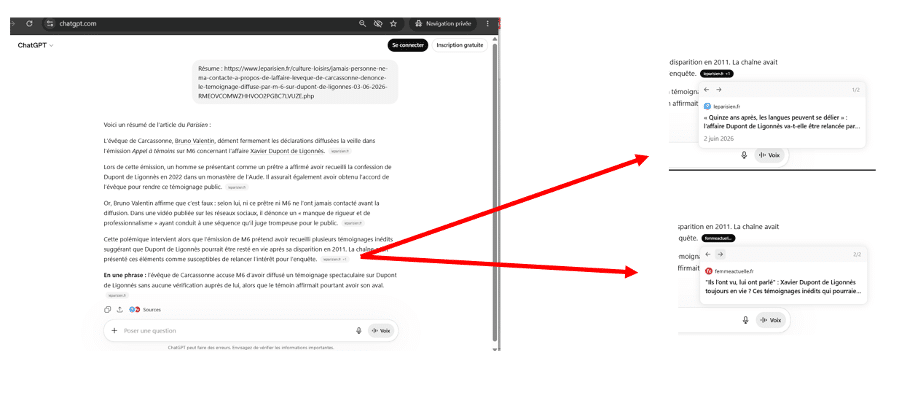
On voit que le système n’a pas seulement utilisée l’URL fournie par l’utilisateur : la réponse ne s’est pas tenue à l’article demandé.
III :
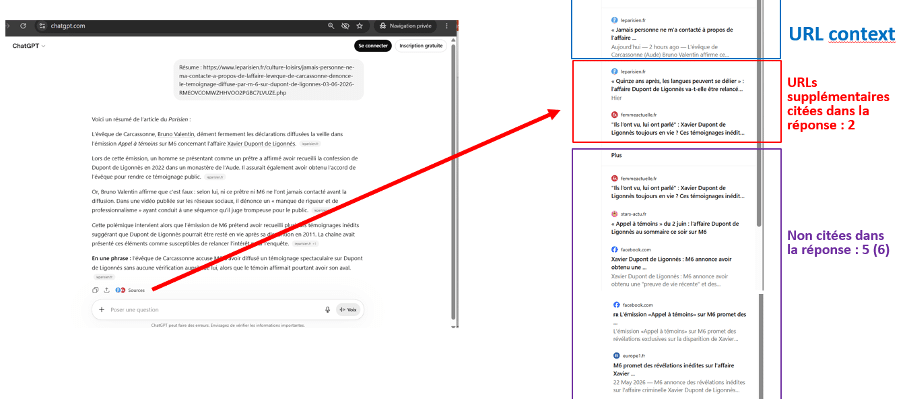
Le système a cité dans sa réponse des URLs supplémentaires, et il en a consulté d’autres qui ne sont pas citées.
Donner une URL précise ne borne donc pas la recherche : le système rouvre une enquête documentaire autour de la page que vous lui avez confiée, au lieu de s’y limiter. Le résumé d’un article devient, en coulisse, une synthèse de plusieurs sources, dont une seule a été demandée.
IV :
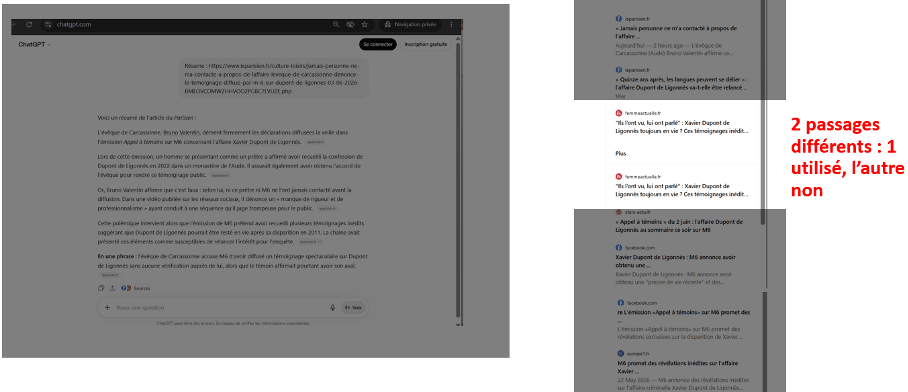
Enfin dernier élément ici, à l’intérieur d’une même source fournie. Le système a isolé deux passages distincts de l’article : il en a utilisé un, et laissé l’autre de côté. En réalité, une page ou un document n’est presque jamais transmis entier au modèle : il est fragmenté en morceaux, qu’on appelle des chunks, dont seuls quelques-uns sont retenus, comparés, puis injectés dans la réponse.
Les informations que vous obtenez dans une réponse générée, reposent donc sur une fraction sélectionnée des pages retenues pour construire cette réponse, et non sur les pages dans leur entièreté. Ceci est valable pour tous les schémas de grounding de toutes IA conversationnelles.
Crawlé, utilisé, cité, montré, listé : cinq états distincts
Ces deux cas nous fournissent une première grille de lecture. Si on a tendance à traiter comme équivalents cinq états par lesquels un contenu peut passer dans cette mécanique de grounding, en réalité ils ne se recouvrent pas.
- Un contenu peut être crawlé : un robot est venu le chercher, il laisse une trace, un hit, dans les logs du site. Ce hit ne dit rien de la suite.
- Le contenu peut ensuite être utilisé, c’est à dire il peut entrer dans le contexte fourni au modèle, mais toujours en morceaux, jamais en entier – c’est le chunking qui découpe et fourni au modèle des extraits pour construire la réponse.
- Il peut être cité, rattaché à une affirmation de la réponse, sans que l’éditeur ne sache à quel endroit, sous quelle forme, ni combien de fois. Aucun signal d’utilisation n’est envoyé par l’IA conversationnelle à l’éditeur.
- Il peut être montré, rendu visible à l’écran, et, on l’a vu avec l’exemple du PSG, parfois sans être listé. Là non plus l’éditeur n’a aucune visibilité sur l’utilisation de son contenu.
- Il peut enfin être listé comme source primaire ou secondaire dans le panneau dédié, ce qui ne recouvre ni l’ensemble de ce qui a été utilisé, ni l’ensemble de ce qui a été montré. Là encore, aucune information n’est transmise à l’éditeur.
Crawlé, utilisé, cité, montré, listé : chacun de ces états est un ensemble distinct, et aucun n’est l’image fidèle des autres. C’est la raison pour laquelle un hit de ChatGPT-user dans les logs d’un site ne prouve rien de précis. Il ne signifie pas que le contenu a été cité dans une réponse, ni qu’il a servi à la générer, ni qu’il a été affiché comme source. Il signifie seulement qu’un robot est passé.
Aucun signal ne mesure l’influence réelle
Pour l’utilisateur, la conséquence de tout ce dispositif et de cette UX, est que les sources affichées donnent un sentiment de vérifiabilité supérieur à ce qu’elles permettent réellement. On peut cliquer sur ce qui est montré, mais ce qui est montré n’est qu’une part de ce qui a servi, et rien ne garantit qu’un lien affiché soutienne effectivement l’affirmation à laquelle il est accolé. La réponse est partiellement auditable, et cette part d’auditabilité est mise en avant comme si elle valait pour le tout.
Pour l’éditeur ensuite, la difficulté est plus profonde. Aucune des unités qu’il peut observer ne mesure l’influence réelle de son contenu sur la réponse produite. Le nombre de hits surévalue cette influence, puisque la plupart des passages ne débouchent sur rien de visible. Le nombre de citations affichées la sous-évalue, puisque l’essentiel de ce qui est utilisé reste invisible. Et le trafic renvoyé, marqué par le fameux utm_source, ne capte qu’une fraction marginale et tardive du phénomène. Le hit, qui est la donnée la plus facile à compter, ne dit rien sur la visibilité. En revanche, ce hit est bien le signal qu’un bot est venu récupérer un contenu.
Ce qu’un hit veut dire, et ce qu’il ne dit pas
La promesse du grounding, c’est l’auditabilité : une réponse dont on peut examiner les appuis, au lieu d’une réponse qu’il faut croire sur parole. Cette promesse n’est pas totalement vide. Mais vue du côté des contenus, l’auditabilité reste minimale.
- L’utilisateur voit des sources. Mais il ne voit ni le périmètre réel de la recherche, ni les sources écartées, ni les arbitrages qui ont conduit à retenir certains passages plutôt que d’autres, ni la part des contenus utilisés sans jamais être affichés.
- L’éditeur, lui, voit des passages de bots et de crawlers dont il ne peut presque rien déduire.
Le brouillage est d’ailleurs entretenu par tous les acteurs de l’IA. Les finalités évoluent, les robots se multiplient. Chez OpenAI, OAI-SearchBot et ChatGPT-user se croisent sur une même requête. Chez d’autres fabricants d’IA, les choses peuvent être encore plus opaques. Claude, le chatbot et modèle d’Anthropic mélange indexation à l’avance, récupération en temps réel et utilisation d’index tiers comme celui de Brave. Enfin, nous voyons apparaitre des user-agents spécifiques pour les usages dits “agents” – Google est en train de spécifier activement cette partie. Finalement, à mesure que ces systèmes deviennent plus “capables”, dire ce qu’ils font avec les contenus devient de plus en plus difficile.
La traçabilité affichée dans les réponses des chabots n’est pas la traçabilité réelle. C’est peut-être le point à retenir avant de compter ses hits, mesurer sa “visibilité” ou encore de se réjouir d’une citation : aucun de ces signaux, pris isolément, ne dit ce qu’on lui fait dire.
Seuls les fabricants d’IA conversationnelles ont toutes les données et peuvent tracer de bout en bout toute la chaine qui mène à la réponse générée pour un utilisateur. Les éditeurs, eux, savent seulement qu’ils sont massivement crawlés.
